
NVIDIA, yapay zeka alanındaki önemli bir gelişme ile karşımıza çıkıyor. Şirket, “Nemotron-CC” adını verdiği büyük bir İngilizce AI eğitim veritabanını tanıttı. Bu kapsamlı veritabanı, toplamda 6.3 trilyon token içeriyor ve bunların 1.9 trilyonu sentetik verilerden oluşuyor. NVIDIA, bu veritabanının, büyük dil modellerinin (LLM) eğitiminde daha önce geliştirilen en detaylı kaynaklardan biri olduğunu vurguladı. Şirket, özellikle akademik ve ticari alanlarda bu yeni kaynak sayesinde önemli değişiklikler yaşanacağını belirtti. İşte konunun detayları…
NVIDIA 6.3 trilyon tokenli yapay zeka eğitim veritabanı Nemotron-CC modelini tanıttı
Nemotron-CC veritabanının oluşturulmasında büyük oranda Common Crawl platformundan alınan veriler kullanıldı. Bu veriler, sistematik bir işleme ve filtreleme prosedürü ile işlenerek yüksek kaliteli bir alt küme olan Nemotron-CC-HQ’ye dönüştürüldü. NVIDIA, bu veritabanını “büyük dil modelleri için mükemmel bir eğitim kaynağı” olarak tanıtıyor.

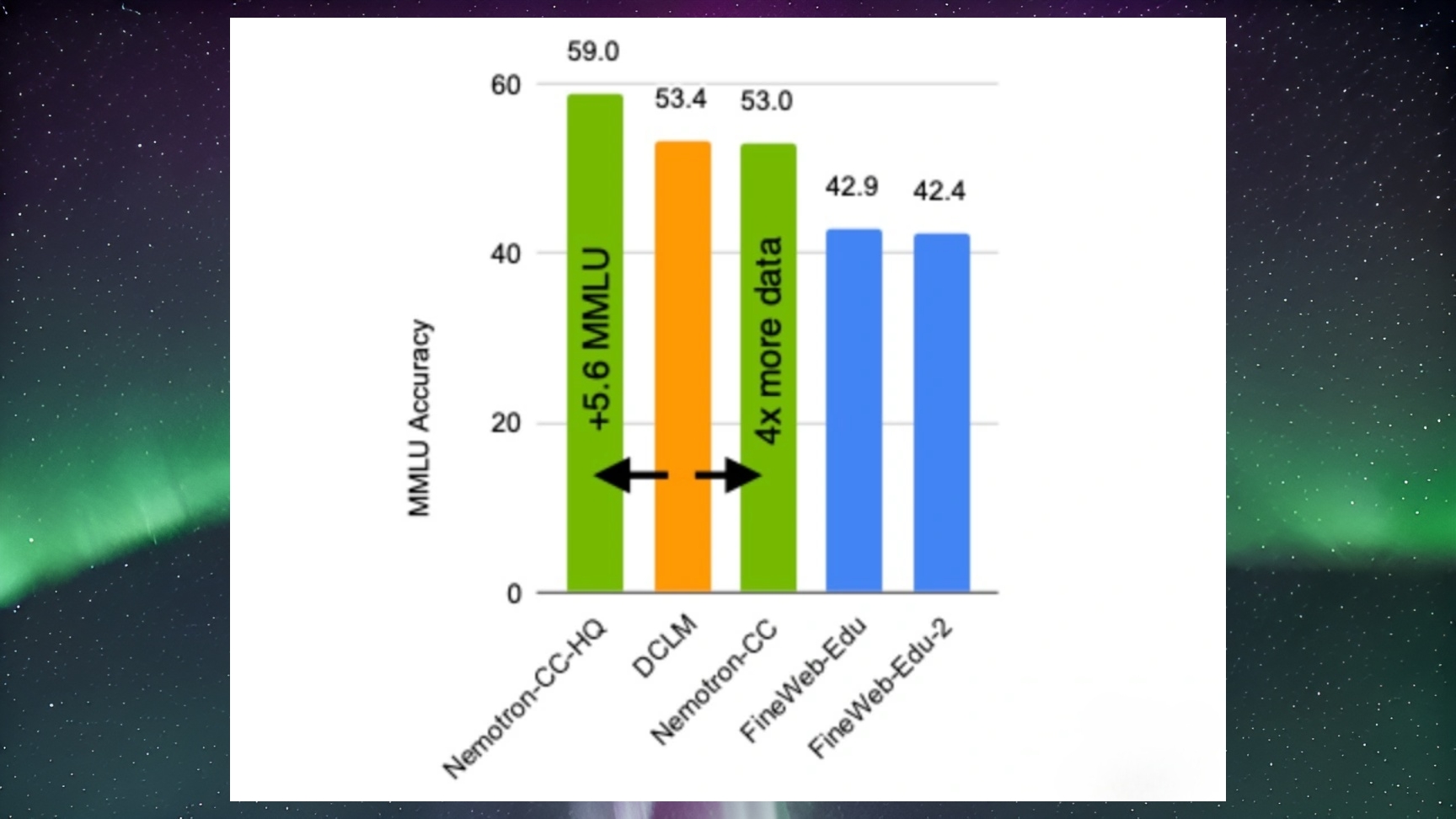
Bu yenilik, mevcut eğitim veritabanlarının ölçek ve kalite sorunlarına çözüm sağlaması bekleniyor. Özellikle Deep Common Crawl Language Model (DCLM) gibi önde gelen açık kaynak veritabanları ile kıyaslandığında, Nemotron-CC’nin daha üst düzey bir performans sunması mümkün gözüküyor. NVIDIA, Nemotron-CC ile eğitilen modellerin çeşitli testlerde gözlemlenen iyileştirmelerde dikkate değer sonuçlar ürettiğini bildirdi. Örneğin:
- MMLU (Massive Multitask Language Understanding) testlerinde mevcut sistemlerden 5.6 puan daha fazla başarı sağlandı.
- 80 milyar parametreye sahip modeller, MMLU testlerinde 5 puan, ARC-Challenge testlerinde ise 3.1 puan artış gösterdi.
- Nemotron-CC’nin, diğer yüksek kaliteli veritabanları ile karşılaştırıldığında 10 farklı görevde ortalama 0.5 puanlık bir performans artışı sağladığı ifade edildi.
Elde edilen bulgular, Nemotron-CC’nin büyük dil modellerinin eğitimi ve performansı üzerindeki potansiyel etkisini gözler önüne seriyor. Ayrıca, NVIDIA, veritabanının geliştirilmesi sürecinde model sınıflandırıcılar ile sentetik veri yeniden ifade etme tekniklerinden (rephrasing) faydalandığını duyurdu. Bu yöntemler, veritabanındaki veri çeşitliliği ve kalitesini arttırmak amacıyla kullanıldı. Bunun yanı sıra, geleneksel veri filtreleme yöntemlerinin bazı kısıtlamalarının gevşetilmesiyle yüksek kaliteli tokenların sayısının artırılması hedeflendi.
NVIDIA, Nemotron-CC veritabanını Common Crawl platformu üzerinde kullanıcıların erişimine sundu ve bu veritabanının dökümantasyonunu yakında şirketin GitHub sayfasında yayınlayacağını açıkladı. Böylece hem akademisyenler hem de ticari kullanıcılar










Yorum Yap